对开发者而言,我们习惯各种各样的仓库,比如 docker 的 hub.docker,再比如 python 的 pypi 库,nodejs 的 npm 库等等。人工智能领域还没有比较集中且受众广泛的库,本篇就来尝鲜下Activeloop提供 AI 数据集库。
0. 为啥需要一个公共的数据集库
众所周知,公共库可以极大的方便我们找资源,在这之前,很多资源都是直接存储在 GitHub 或谷歌云、OneDrive。虽然在 colab 上使用也比较顺手,但是每个资源都需要人为预处理,其实是不易于推广的。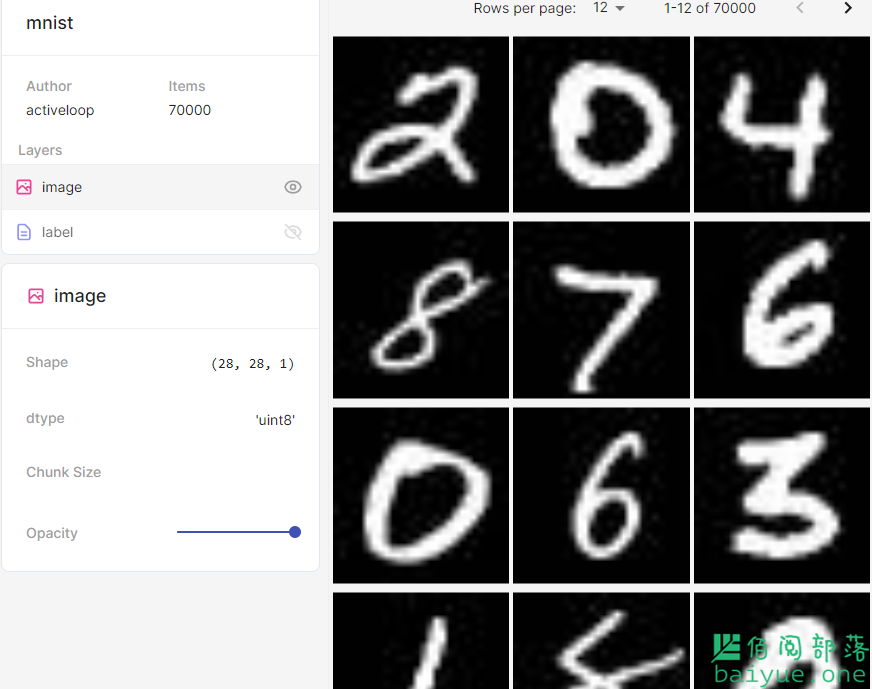 按照 Activeloop 的思路,认为“数据科学家和 ML 科学家应该专注于训练模型,但现在我们都在花大量时间管理和预处理数据。”,而 Activeloop 正是为了解决这些花样繁多的数据集而做的公共 hub。
按照 Activeloop 的思路,认为“数据科学家和 ML 科学家应该专注于训练模型,但现在我们都在花大量时间管理和预处理数据。”,而 Activeloop 正是为了解决这些花样繁多的数据集而做的公共 hub。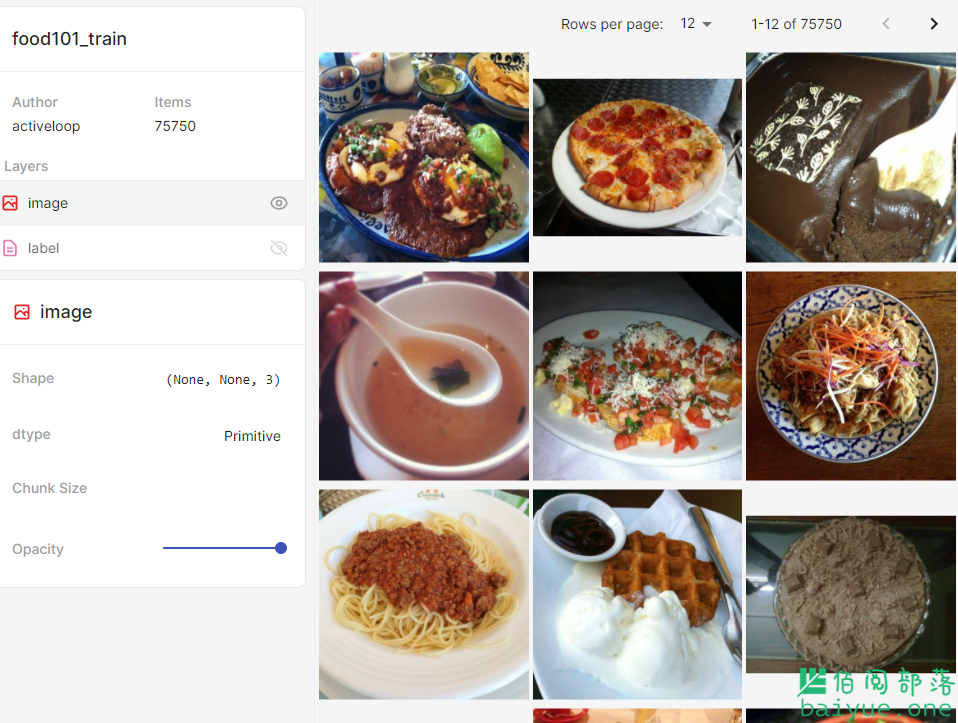
1. Activeloop 设计的公共 HUB 有哪些优势?
- 以版本控制工具储存/回复大型数据库。
- 像 Google Docs 一样协作: 多个数据科学家同时处理一组数据,并且没有同步冲突
- 同时从多个设备访问
- 与您的 ML 工具整合, 比如 Numpy, Dask, Ray, PyTorch,TensorFlow
- 可部署在 Google Cloud, S3, Azure,和 Activeloop (预设选择,并且是免费的!)
- 随心所欲地创建任意大小的储存数组. 您甚至可以储存 100k x 100k 大小的图片!
- 动态地保存样本的形状. 因此您可以把大数组和小数组储存为一条数组
- 无需冗长的操作,用几秒种即可可视化数据中的片段
其中内容包括图像、文字、音频、 histograms、seq、tweet 等。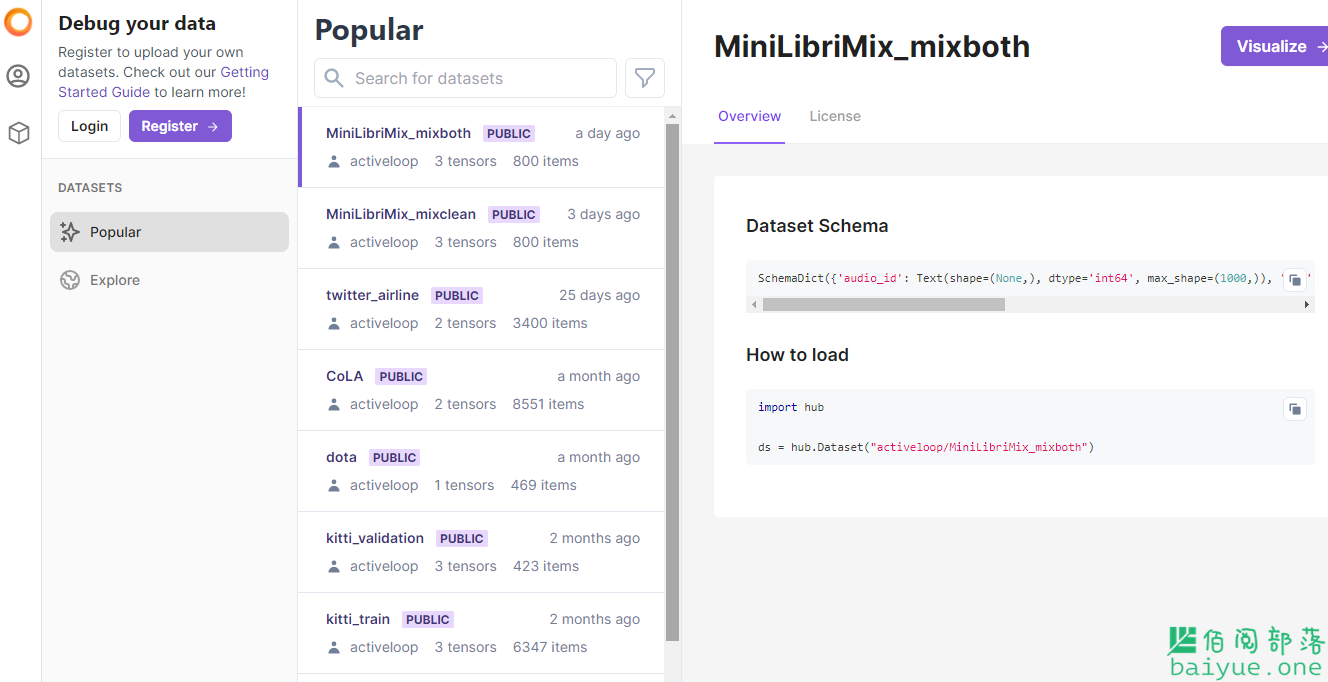
2. 简易使用方法
安装:pip install hub
使用:
import hub
mnist = Dataset("activeloop/mnist") # loading the MNIST data lazily
# 数据集展示
import matplotlib.pyplot as plt
plt.imshow(mnist['image', 10].compute())
# 直接训练
import torch
mnist = mnist.to_pytorch(lambda x: (x["image"], x["label"]))
train_loader = torch.utils.data.DataLoader(mnist, batch_size=1, num_workers=0)
for image, label in train_loader:
# Training loop here更多教程,可以参考 hub 的相关文档。基本上你能听说的数据库资源都包含了,没有的话还可以自己提交,一些图片类资源还支持线上预览。
3. 参考资源
- https://app.activeloop.ai/datasets/popular
- https://www.activeloop.ai/