佰阅科技
佰阅部落
博客
项目
!博客已完成rust-nuxt3重构,欢迎体验!
重度依赖 AI 后,警惕长期摆烂
AI 依赖症导致人类思考能力下降,需警惕长期摆烂,通过自我反思、目标设定和多样化兴趣保持成长。
10 个月前
2.4k
3
我为什么喜欢 RUST
谈谈个人对 rust 的思考
1 年前
3.5k
12
2023 下半年复盘笔记:何以成就伟大?
2023 下半年复盘笔记:何以成就伟大?个人笔记
2 年前
2.8k
11
2023上半年复盘笔记:回归匆匆,独行依旧
2023上半年的试错经历,感觉无暇顾及,匆匆忙碌。
2 年前
3.5k
15
2022下半年复盘笔记:为何有心无力?
个人输出的变化和创意的重要性
3 年前
4.7k
8
ChatGPT:首次成功模拟人类智慧,考验人类提出问题的能力
ChatGPT是通用AI,将考验人类提出问题的能力
3 年前
4.2k
1
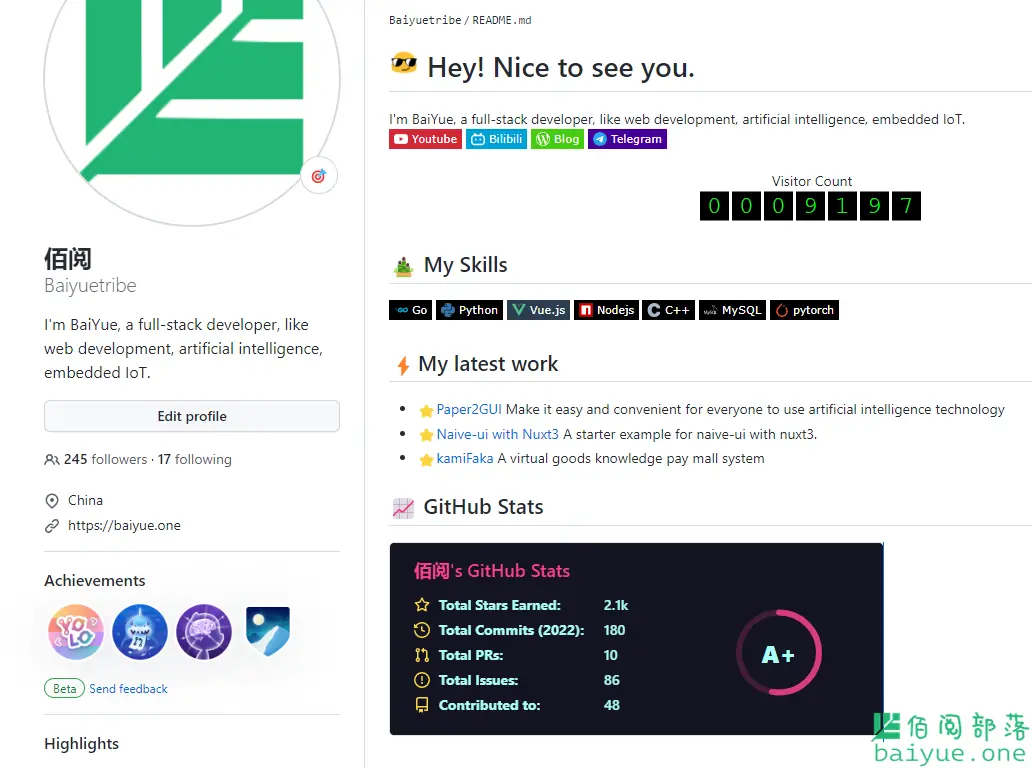
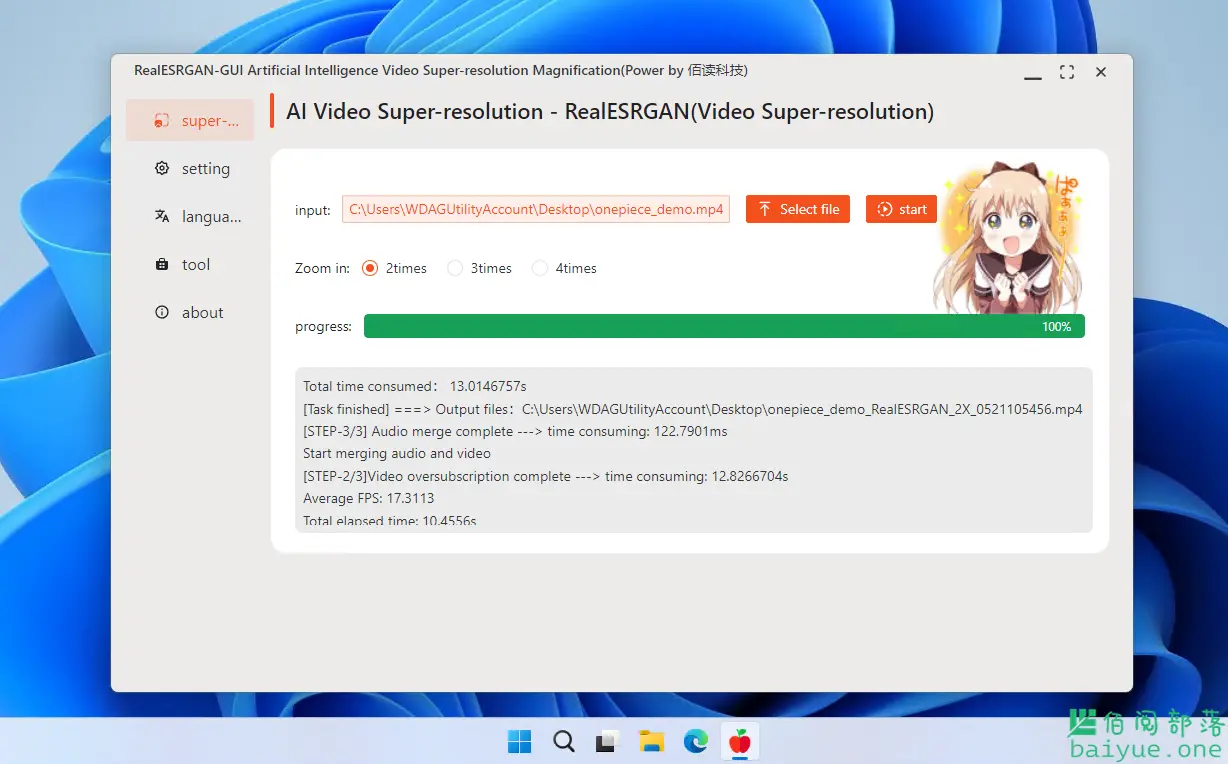
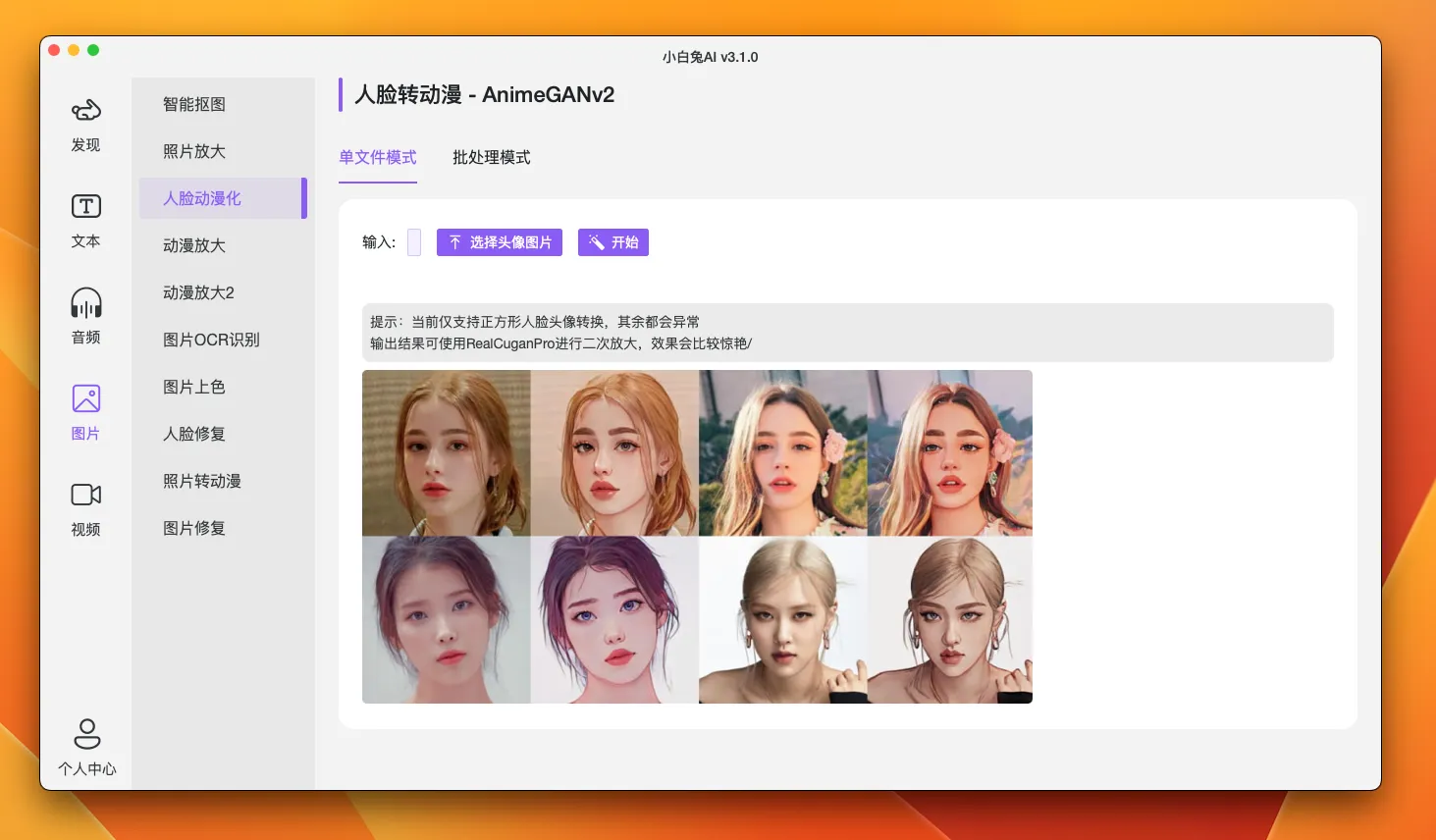
小白兔AI:面向非编程人员的AI人工智能工具箱
提供面向非编程人员的AI人工智能工具箱
3 年前
7.7k
10
2022上半年复盘笔记:重新定义零
创意如何变为现实?技术陷阱如何阻碍新品诞生?
3 年前
5.5k
19
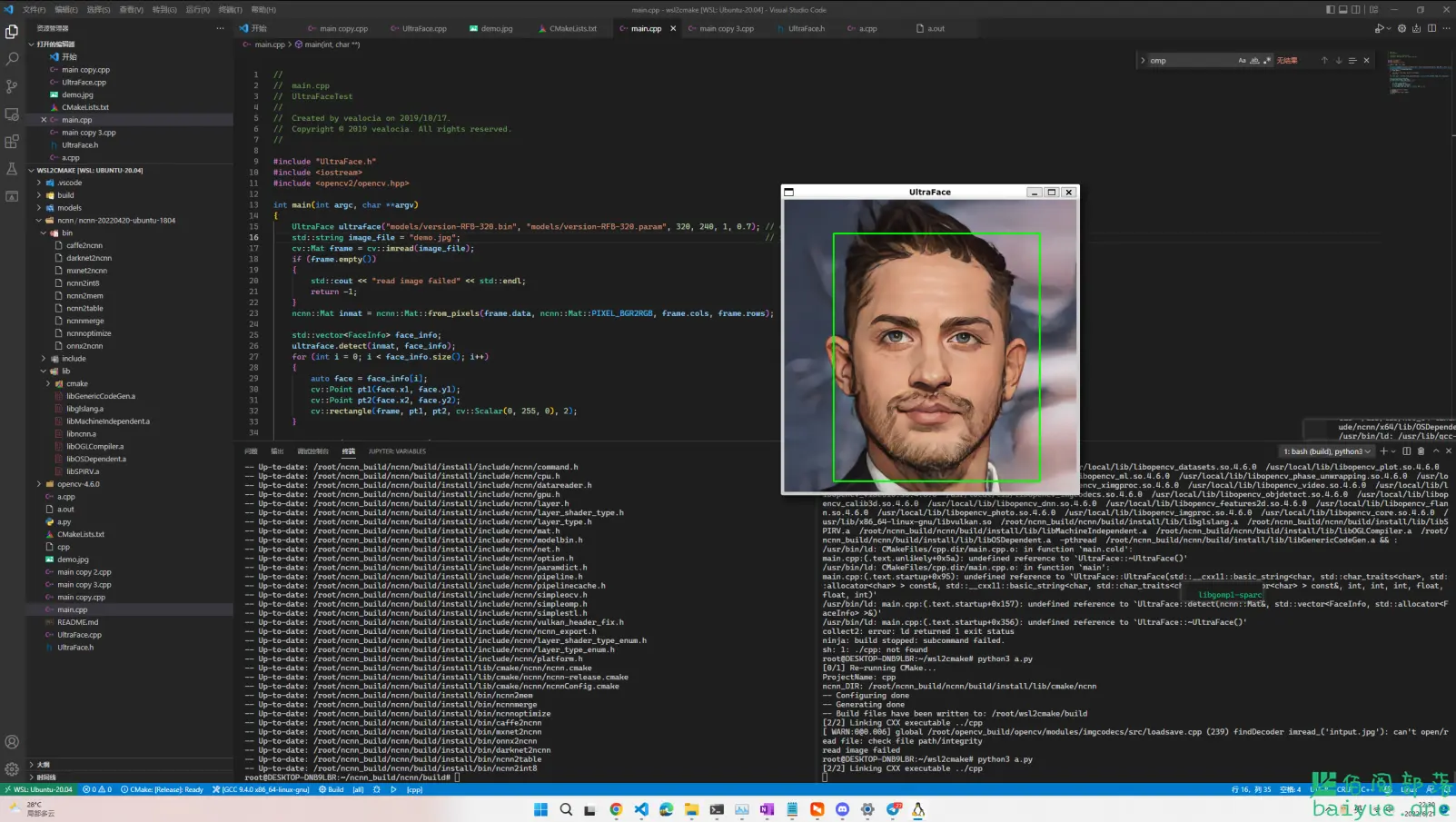
如何在Windows子系统WSL2中安装并使用NCNN
在Windows子系统WSL2中安装并使用NCNN
3 年前
6.3k
0
NCNN学习笔记:谁能统一人工智能终端部署?
ncnn是一个高性能神经网络前向计算框架,简单易用,跨平台。
3 年前
5.2k
2
1
2
3
4
5
22
分类专题
人工智能
信息安全
其他笔记
实用工具
搭建教程
数据可视化
联系方式
邮箱
TG
QQ
近期项目
夸克基地
网站统计
累计发布:212 篇
总点赞量:1365
累计运行:6 年 321 天
建站日期:2018-10-25